탐색 알고리즘 (BFS & DFS)
참고 원본 - DFS & BFS
Table of Contents
탐색 ?
- 탐색 알고리즘이란 많은 데이터 중 원하는 데이터가 어디 있는지 찾는 과정
- 대표적인 탐색 알고리즘으로는 BFS, DFS가 있음
- BFS (Breath First Search) $\rightarrow$ 너비 우선 탐색으로, Queue 자료 구조를 활용
- DFS (Depth First Search) $\rightarrow$ 깊이 우선 탐색으로, Stack 자료 구조를 활용
Stack & Queue
-
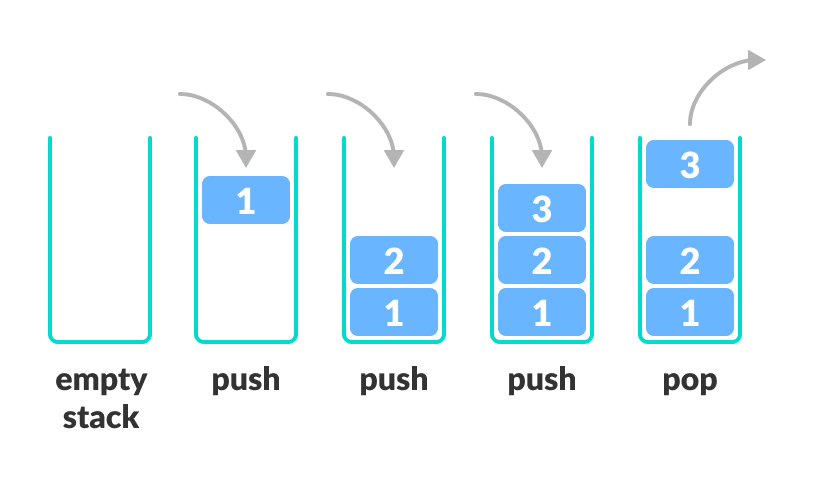
Stack
- 가장 먼저 들어온 데이터가 가장 마지막에 나가는 구조
- 가장 마지막으로 들어온 데이터가 가장 먼저 나가는 구조
- LIFO (Last In First Out) 자료 구조
- Stack에 데이터를 넣는 것을 Push
- Stack에서 데이터를 꺼내는 것을 Pop이라고 합니다.
- 입구 및 출구가 동일한 곳에 물건을 넣는 형태를 생각하면 편함 ex) 상자 쌓기
-
Queue
- 가장 먼저 들어온 데이터가 가장 먼저 나가는 구조
- 가장 마지막에 들어온 데이터가 가장 마지막에 나가는 구조
- FIFO (First In First Out) 자료 구조
- Queue에 데이터를 넣는 것을 enqueue
- Queue에서 데이터를 꺼내는 것을 dequeue라고 합니다.
- 한 줄로 줄 서는 형태를 생각하면 이해하기가 쉽습니다. ex) 은행 번호표 시스템

Python에서의 Stack & Queue
- Python에서 기본으로 제공하는 자료형을 이용하여 Stack과 Queue를 사용할 수 있음
- Stack
List자료형을 이용append,pop메소드를 이용하여, 데이터를 push 및 poplen(stack_data)함수를 이용하여, 내부 데이터 개수 확인 가능
stack_data = [] stack_data.append(1) # [1] stack_data.append(3) # [1, 3] stack_data.append(10) # [1, 3, 10] stack_data.append(2) # [1, 3, 10, 2] stack_data.append(5) # [1, 3, 10, 2, 5] 왼쪽이 가장 먼저 들어간 데이터 print(stack_data[::-1]) # [5, 2, 10, 3, 1] 최상단 데이터부터 출력 print(stack_data.pop()) # 5 print(stack_data.pop()) # 2 print(stack_data.pop()) # 10 print(stack_data[::-1]) # [3, 1] 최상단 데이터부터 출력 - Queue
deque자료형을 이용from collections import deque를 통해 사용 가능append및popleft메소드를 이용하여, 데이터를 enqueue, dequeuereverse메소드를 이용하여, 순서를 역순으로 변경 가능List자료형을 사용할 시, 시간 복잡도가 더 증가하므로,deque사용 권장len(queue_data)함수를 이용하여, 내부 데이터 개수 확인 가능
from collections import deque queue_data = deque() queue_data.append(5) # [5] queue_data.append(2) # [5, 2] queue_data.append(3) # [5, 2, 3] queue_data.append(7) # [5, 2, 3, 7] queue_data.append(2) # [5, 2, 3, 7, 2] print(queue_data.popleft()) # 5 print(queue_data.popleft()) # 2 queue_data.append(10) # [3, 7, 2, 10] print(queue_data) # deque([3, 7, 2, 10]) 왼쪽이 가장 먼저 들어간 데이터 queue_data.reverse() # 순서를 반대로 변경 print(queue_data) # deque([10, 2, 7, 3]) 왼쪽이 가장 먼저 들어간 데이터
C++에서의 Stack & Queue
- C++ STL에 포함된 Stack 및 Queue를 사용할 수 있음
- Stack
#include <stack>으로 사용 가능stack<int>와 같은 형태로 특정 타입의 스택을 사용 가능push,pop메소드를 사용하여 데이터 넣기 및 꺼내기 가능top메소드를 사용하여, 최상단의 데이터 확인 가능size메소드를 사용하여, Stack 내부의 데이터 개수 확인 가능empty메소드를 사용하여, Stack이 비어있는지 확인 가능
- Queue
#include <queue>으로 사용 가능queue<int>와 같은 형태로 특정 타입의 큐 사용 가능push,pop메소드를 사용하여 데이터 넣기 및 꺼내기 가능front메소드를 사용하여, 첫 번째 원소 확인 가능back메소드를 사용하여, 마지막 원소 확인 가능size메소드를 사용하여, Queue 내부의 데이터 개수 확인 가능empty메소드를 사용하여, Queue가 비어있는지 확인 가능
재귀 함수
- 자기 자신을 다시 호출하는 형태의 함수
- 지속적으로 호출하므로, 종료 조건이 꼭 필요
- 팩토리얼, 피보나치 수열, 하노이 타워 등이 대표적
- 특징
- 수학적 점화식을 바로 코드를 옮길 수 있음
- 이론적으로 모든 재귀함수는 반복문을 이용하여 구현 가능 (상황에 따라, 성능은 차이가 있을 수 있음)
- 재귀 함수 사용 시, 메모리의 Stack 프레임을 사용 (Stack 자료 구조와 유사)
def factorial_recursive(_N):
if _N <= 1:
return 1
else:
return N * factorial_recursive(_N - 1)
DFS (Depth First Search)
- 최대한 깊게 들어가면서 데이터를 확인하는 방법
- Stack 자료 구조 or 재귀 함수를 사용
- 시작 Node를 Stack에 삽입하고 방문 처리
- Stack 최상단 Node와 인접한 Node 확인
- 인접한 Node가 있을 경우, 그 중 1개를 Stack에 넣고 방문 처리 (넣는 기준이 필요)
- 인접한 Node가 없을 경우, Stack 최상단 Node 꺼내기
- 위의 과정(1, 2)을 Stack에 값이 없을 때까지 반복
graph는 2차원 list (N번 Node와 인접한 번호가 저장되어 있음, 0번을 비워주는 것이 헷갈리지 않을 수 있음)visited는 해당 Node가 방문되었는 지 여부 표시 ([False] * (N + 1)리스트)- 0을 사용하지 않는게 더 직관적이고, 이를 위해서 N + 1 크기의 리스트가 필요
def dfs(graph, start, visited)
visited[start] = True
print(start, end=' ')
for i in graph[start]:
if not visited[i]:
dfs(graph, i, visited)
stack_data = []
visited[start] = True
stack_data.append(start)
print(start, end=' ')
while stack_data:
now = stack_data[-1]
for i in graph[now]:
if not visited[i]:
stack_data.append(i)
visited[i] = True
print(i, end=' ')
break
else:
stack_data.pop()
BFS (Breath First Search)
- 최대한 넓게 데이터를 확인하는 방법 (가까운 Node 부터 탐색)
- Queue 자료 구조 사용
- 시작 Node를 Queue에 삽입
- Queue에서 하나를 꺼내고 방문 처리, 인접한 Node 중 방문하지 않은 Node 모두 삽입
- Queue의 데이터가 없을 때까지, 2의 과정을 반복
- BFS는 가까운 곳부터 탐색하는 특징을 이용하여, Node 사이 이동 비용이 동일한 상황에서의 최단거리를 계산하는데 사용 가능
from collections import deque
def bfs(graph, start, visited):
queue = deque([start])
while queue:
now = queue.popleft()
visited[now] = True
print(now, end=' ')
for i in graph[now]:
if not visited[i]:
queue.append(i)
음료수 얼려 먹기 문제
-
N $\times$ M 얼음 틀
-
뚫려 있는 곳은 0, 막혀 있는 곳은 1
-
얼음틀에 얼음을 얼려서, 얻을 수 있는 얼음의 개수 출력
-
Input : N, M (세로길이, 가로길이) (1 <= N, M <= 1000), 얼음틀의 값(N $\times$ M의 값)
-
Output : 얼려진 얼음의 개수
-
풀이
- 순차적으로 얼음틀을 확인하여, 0인 경우 그 위치에서 BFS or DFS를 이용하여 붙어 있는 0인 곳을 모두 1처리한 후, 얼음 개수 += 1
- 얼음틀의 모든 위치가 1로 변경되면 종료
- 얼음 개수를 출력
def dfs(x, y):
if x <= -1 or x >= n or y <= -1 or y >= m:
return False
if graph[x][y] == 0:
graph[x][y] = 1
dfs(x - 1, y)
dfs(x + 1, y)
dfs(x, y - 1)
dfs(x, y + 1)
return True
return False
n, m = map(int, input().split())
graph = []
for i in range(n):
graph.append(list(map(int, input())))
result = 0
for i in range(n):
for j in range(m):
if dfs(i, j) == True:
result += 1 # 얼음의 개수
print(result)
미로 탈출
-
N $\times$ M 미로
-
이동할 수 있는 영역은 0, 괴물이 있어서 이동할 수 없는 곳은 1
-
한 번에 한 칸씩 이동이 가능
-
Input : N, M (세로길이, 가로길이) (4 <= N, M <= 200), 미로의 값(N $\times$ M의 값, 0 or 1)
-
Output : (N, M) 까지 이동에 필요한 최소 이동 칸 (시작 위치 및 마지막 위치 포함)
-
풀이
- 해당 문제는 모든 위치를 꼭 다 탐색할 필요는 없으며, (N, M)까지의 최소 거리만 계산하면 종료 가능
- 따라서, DFS를 사용하는 것 보다는 BFS를 사용하는 것이 유리한 문제
- BFS를 이용하여 연결된 통로를 탐색하며, 이동한 거리로 해당 위치를 업데이트
- (N, M)의 값이 업데이트가 되면 종료
from collections import deque
def bfs(x, y, _graph):
queue = deque()
queue.append((x, y))
while queue:
x, y = queue.popleft()
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if nx < 0 or nx >= n or ny < 0 or ny >= m:
continue
if _graph[nx][ny] == 0:
continue
if _graph[nx][ny] == 1 and not (nx == 0 and ny == 0):
_graph[nx][ny] = _graph[x][y] + 1
queue.append((nx, ny))
if _graph[-1][-1] != 1:
break
print(_graph[-1][-1])
n, m = map(int, input().split())
graph = []
for i in range(n):
graph.append(list(map(int, input())))
dx = [1, 0, 0, -1]
dy = [0, 1, -1, 0]
bfs(0, 0, graph)
리뷰
- 전체적으로 BFS 및 DFS를 이용한 탐색에 대해서 알아보았다.
- 이론적으로 모든 데이터를 모두 탐색해야할 경우에는 BFS, DFS 두 가지 모두 다 답을 찾는데 사용할 수 있다.
- 찾는 데이터가 어디에 있느냐에 따라 BFS 및 DFS의 속도에는 약간의 차이가 있을 것 같다.
- DFS가 BFS에 비해 구현이 상대적으로 간단한 것 같다 (재귀 이용 구현)
- BFS의 경우, 가까운 것부터 탐색하는 특징이 있어서, 이를 이용하여 최단 거리 문제를 풀 때도 사용이 가능하다.
- 실제 2D Occupancy Grid Map에서 최단 거리를 계산할 때, BFS와 다른 알고리즘의 속도를 비교하는 것을 많이 보았던 것 같다.